Sub-JEPA: Subspace Gaussian Regularization for Stable End-to-End Latent World Models
💡 Compute-friendly: All experiments run on a single GPU with ≥24 GB VRAM (e.g. RTX 3090 / 4090) — no multi-GPU setup or large cluster required.



TL;DR:
Background: World models learn compact latent representations from raw pixels for planning. LeWorldModel (LeWM), from LeCun's group at NYU, trains end-to-end using just two losses: next-embedding prediction and SIGReg, which pushes latent embeddings toward an isotropic Gaussian.
The problem LeWM enforces this Gaussian prior over the full high-dimensional embedding space. But environment dynamics live on low-dimensional manifolds — so the global prior is too rigid. LeWM itself struggles most on Two-Room, its lowest-dimensional task.
Our fix Sub-JEPA applies SIGReg inside multiple frozen random orthogonal subspaces instead of the full space, relaxing the global constraint while keeping the anti-collapse effect.
Results Sub-JEPA consistently outperforms LeWM across all four benchmarks, with the largest gain on Two-Room (+10.7 pp). Straighter latent trajectories and better physical state decodability emerge as bonus benefits — no new hyperparameters needed.
Abstract
We propose Sub-JEPA, a latent world model that relocates Gaussian regularization from the full ambient embedding space into low-dimensional random orthogonal subspaces. Latent representations of control tasks typically lie on low-dimensional manifolds; enforcing an isotropic Gaussian prior in the full high-dimensional space introduces an excessive bias that mismatches the task's intrinsic geometry. Sub-JEPA replaces this global prior with independent subspace-level Gaussian constraints, relaxing the bias while preserving the anti-collapse guarantees of LeWorldModel (LeWM). Across four continuous-control benchmarks, Sub-JEPA consistently outperforms LeWM, with gains directly correlated with reductions in effective rank.
Method
A latent world model consists of an encoder
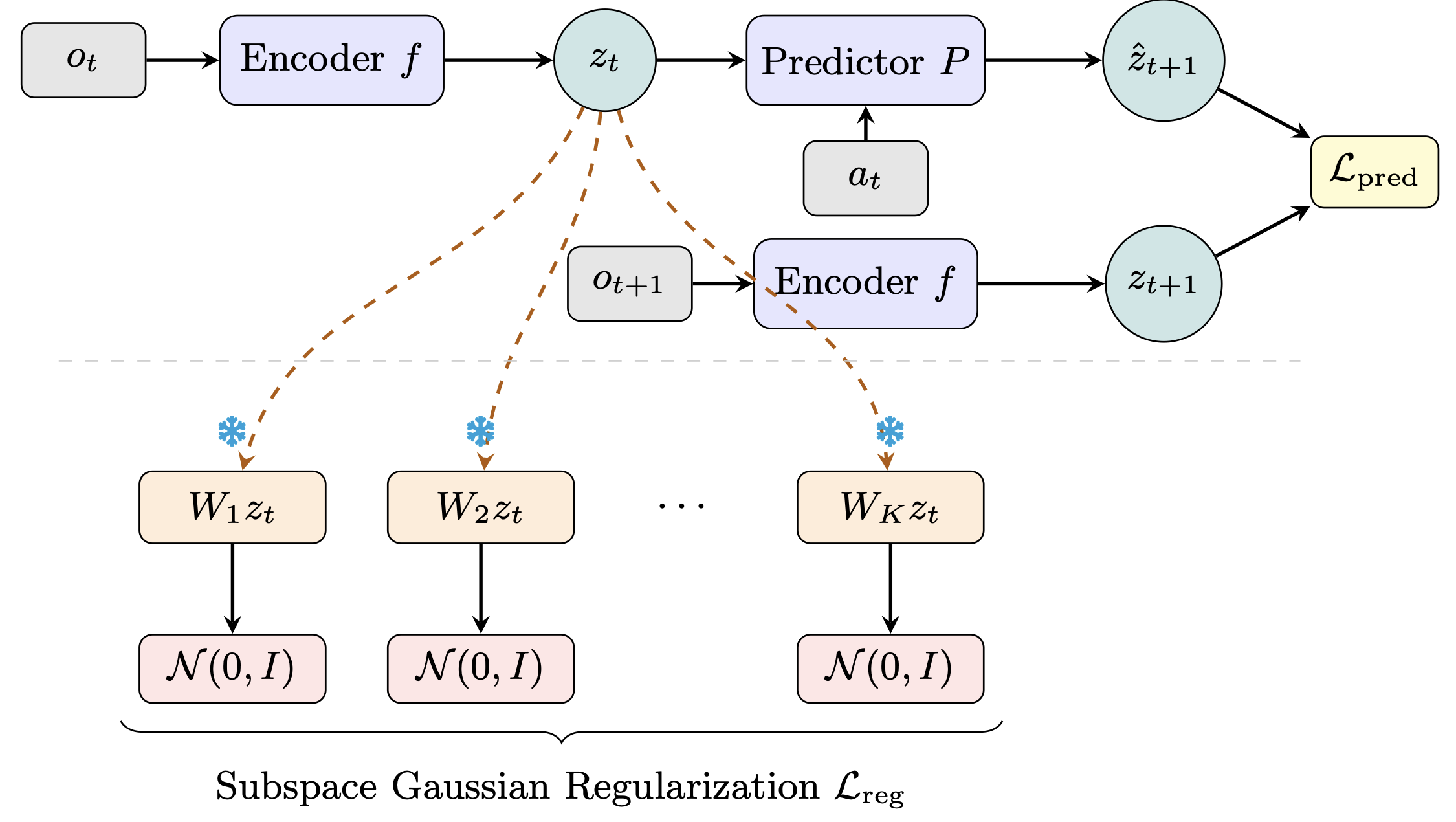
Figure 1. Sub-JEPA encodes consecutive observations into latents via a shared encoder, then trains a predictor with a prediction loss. The key addition (below the dashed line) is a subspace Gaussian regularization loss: the latent is projected onto K frozen random orthogonal subspaces, each independently regularized toward a standard Gaussian.
Orthogonal subspace projection.
LeWM regularizes the full
Multi-subspace Gaussian regularization.
Within each subspace, we apply the Epps–Pulley normality test to random 1D
projections of the subspace embeddings, following LeWM.
The regularization loss averages across all
The total objective combines latent prediction with subspace regularization:
Freezing the projections prevents co-adaptation between the encoder and the regularizer, ensuring consistent Gaussian constraints throughout training.
Results
Sub-JEPA is evaluated on four continuous-control benchmarks trained from raw RGB observations, compared against LeWM, PLDM, and DINO-WM (six seeds, mean ± std).
| Method | Two-Room | Reacher | PushT | OGB-Cube |
|---|---|---|---|---|
| PLDM | 97.00 | 78.00 | 78.00 | 65.00 |
| DINO-WM (w/o proprio.) | 100.00 | 79.00 | 74.00 | 86.00 |
| LeWM | 84.33±4.23 | 82.67±4.42 | 84.67±6.53 | 67.33±5.01 |
| Sub-JEPA (Ours) | 95.00±2.76 | 84.00±4.00 | 89.00±5.33 | 76.33±5.99 |
Figure 2. Effective rank (top) and planning success rate (bottom) across four environments. Environments where Sub-JEPA most reduces effective rank relative to LeWM also show the largest performance gains, suggesting that subspace regularization improves planning by suppressing spurious high-rank variation in the latent space.
The largest gains appear on Two-Room (+10.7%) and OGB-Cube (+9.0%), which also exhibit the largest effective rank reductions. This direct correspondence supports our hypothesis: when task dynamics lie on a low-dimensional manifold, the full-space Gaussian prior forces unnecessarily high rank. Subspace regularization allows the latent geometry to contract toward the task's intrinsic dimensionality.
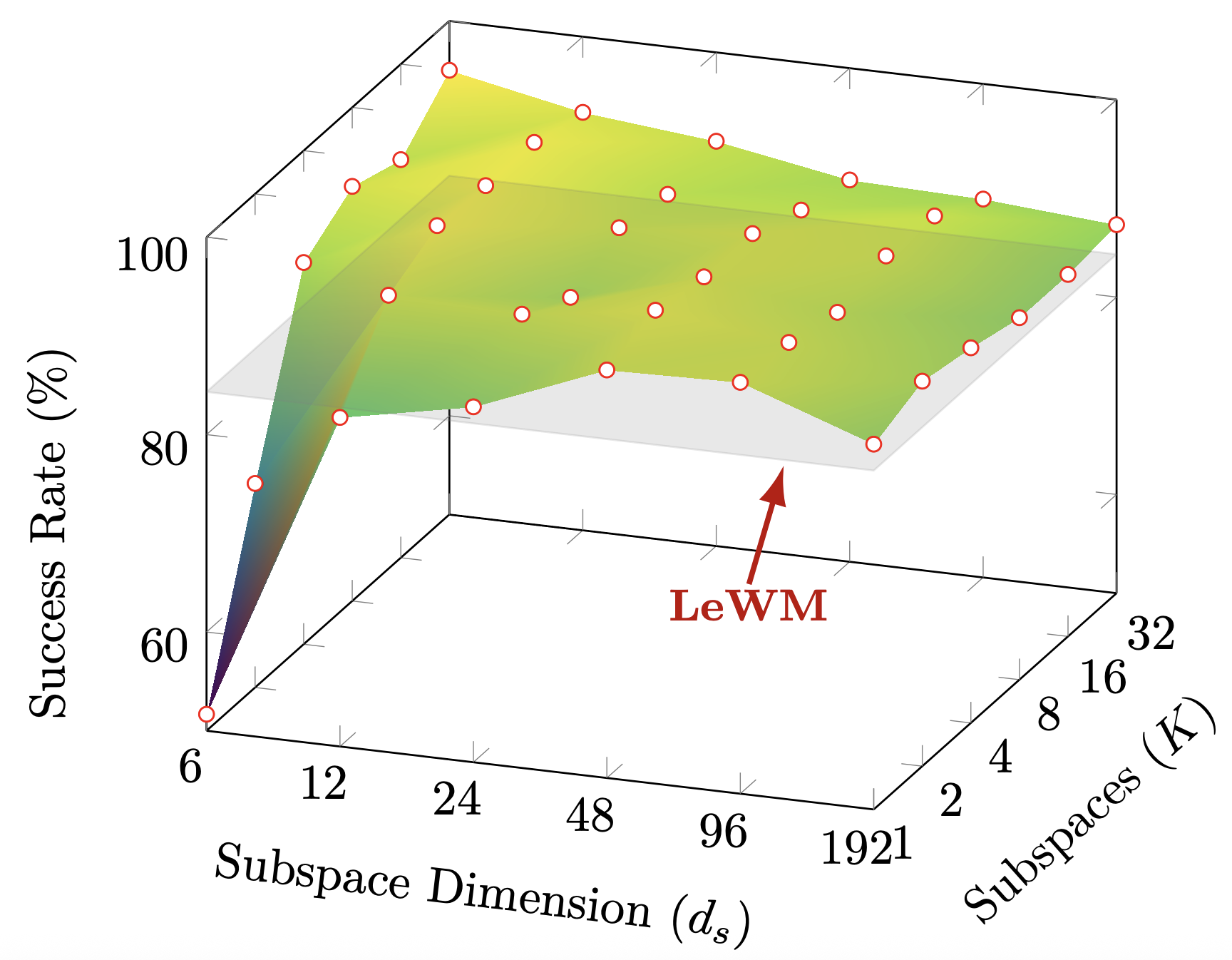
Figure 3. Success rate on Two-Room as a function of the number of subspaces K and subspace dimension ds. The flat plane shows the LeWM baseline. Sub-JEPA exceeds it across a wide mid-range of configurations, indicating robustness to the exact hyperparameter choice.
To verify that Sub-JEPA learns representations better matched to the task geometry, we visualize latent trajectories on Two-Room, where the low intrinsic dimensionality makes the mismatch with the full-space Gaussian prior most pronounced. Consecutive observations are encoded and their [CLS] embeddings are projected to 2D via UMAP, colored by normalized temporal index. Sub-JEPA consistently produces temporally coherent paths across episodes, while LeWM shows less regular temporal structure — suggesting that the full-space prior distorts latent geometry when task dynamics are intrinsically low-dimensional.
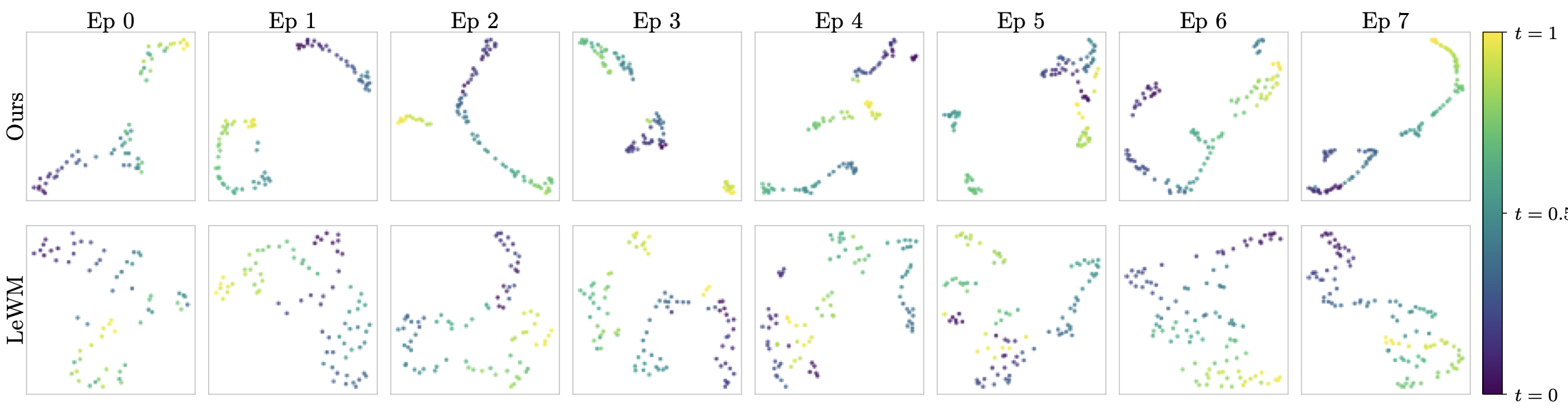
Figure 4. UMAP projections of latent trajectories on Two-Room, colored by normalized temporal index. Sub-JEPA produces well-organized, temporally coherent paths. LeWM exhibits less regular temporal structure, indicating that the full-space Gaussian prior distorts latent geometry when task dynamics are intrinsically low-dimensional.
Following LeWM, we examine latent trajectory geometry via temporal path straightness — how linearly dynamics evolve in latent space, measured by mean cosine similarity between consecutive temporal velocity vectors. Straighter trajectories are particularly desirable for latent world models, where planning quality depends on rollout regularity. As shown in Figure 6, Sub-JEPA consistently produces straighter trajectories than LeWM on both PushT and OGB-Cube, emerging naturally without explicit optimization. This suggests that subspace-wise regularization reduces geometric distortion relative to full-space regularization, offering a geometric explanation for the planning gains in Table 1.
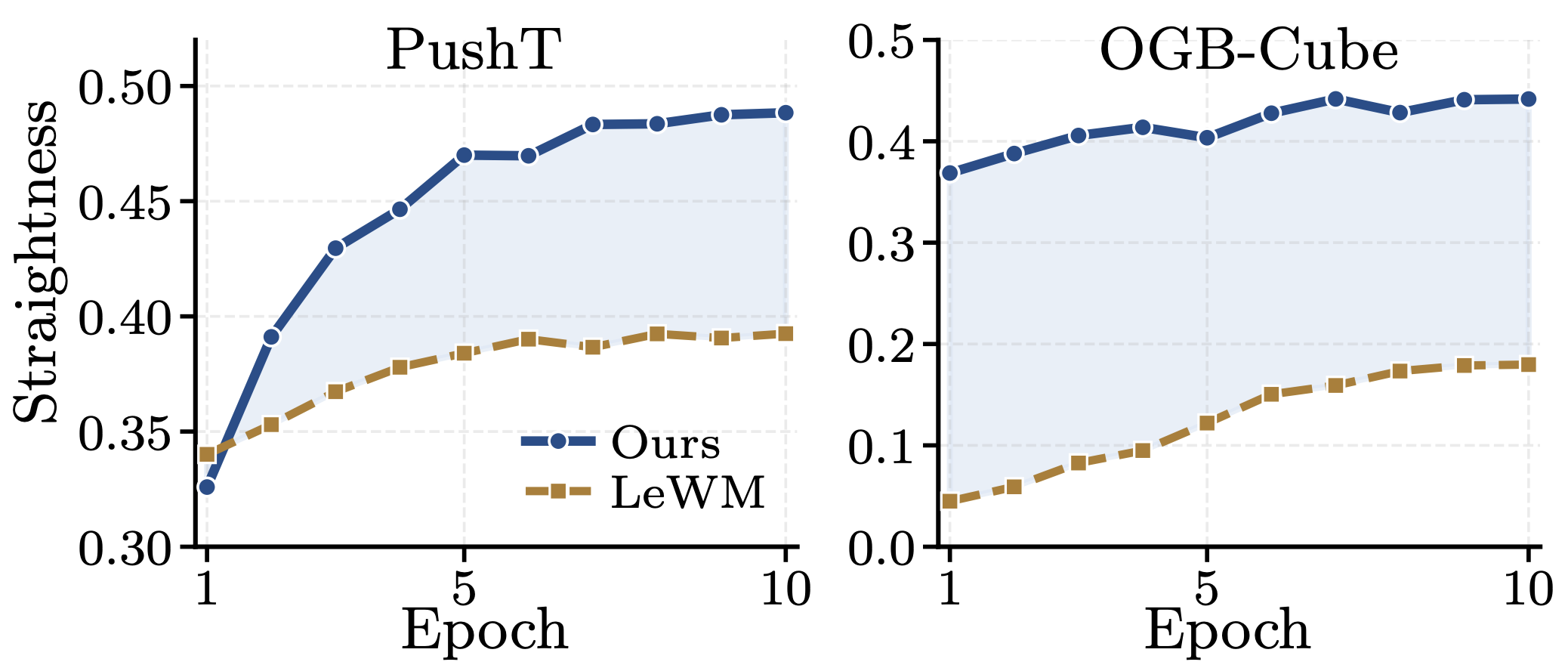
Figure 6. Latent trajectory straightness (mean cosine similarity between consecutive temporal velocities) on PushT and OGB-Cube. Sub-JEPA consistently outperforms LeWM without any explicit straightness objective, suggesting that subspace regularization reduces geometric distortion in latent space.
Conclusion
Sub-JEPA is a minimal modification of LeWM: replace full-space Gaussian
regularization with independent Gaussian constraints in